Ontdek alle mogelijkheden met ApplePY. Bekijk alle features
De robots.txt is een bestand met een reeks aan aanwijzigingen waarmee zoekmachines weten welke pagina’s van een website door zoekmachines moeten worden gecrawld.
Het bestand wordt vaak verkeerd begrepen. Het is niet bedoeld om te voorkomen dat pagina's worden geïndexeerd. Want voeg je de verkeerde instructies toe? Dan kan het zomaar zijn dat Google de website niet meer kan crawlen.
Simpel gezegd, een robots.txt is een gewoon tekstbestand met instructies voor webrobots (ook wel 'spiders' of 'bots' genoemd) die aangeven hoe de website wel of niet moet worden gecrawld. Het robots.txt-bestand bevindt zich in de hoofdmap van de website en kan worden geopend door 'robots.txt' toe te voegen aan de startpagina van een website.
https://www.domeinnaam.nl/robots.txt
De meeste grote CMS-platforms bieden manieren om de robots.txt te bewerken via hun dashboard of door het gebruik van plug-ins waarvoor geen nieuw tekstbestand hoeft te worden gemaakt en opgeslagen, telkens wanneer een wijziging wordt aangebracht.
Alle zoekmachines hebben deze spiders die het internet doorzoeken. De meeste crawlers van zoekmachines respecteren een robots.txt-bestand, maar niet alle spiders. Het robots.txt-bestand dient als instructies voor crawlers over hoe ze door de website moeten navigeren.
Heb je een kleine website, dan hoef je je geen zorgen te maken over het belang van het blokkeren van crawlers van delen van de website. Heb je een grote e-commerce webshop met miljoenen pagina’s, dan is het van groot belang dat de robots.txt correct wordt ingesteld om te voorkomen dat bepaalde pagina's worden gecrawld.
De structuur van een robots.txt-bestand is eenvoudig:
De 'user-agent' verklaart de specifieke crawler. Een voorbeeld van het uitroepen van Google en Bing zou er als volgt uitzien:
User-agent: Googlebot
User-agent: Bingbot
Andere voorbeelden van standaard zoekmachinecrawlers en hun user-agent zijn:
KeyCDN heeft een uitgebreidere lijst met webcrawlers die er zijn.
User-agent tips:
User-agent: ChatGPT-User
Disallow: /
Het bovenstaande voorbeeld laat zien hoe jij kunt voorkomen dat ChatGPT de hele website crawlt. Als je wilt dat de website wordt gecrawld, kun je de disallow leeg laten of de instructie 'Allow' gebruiken en een lijst maken van de delen van de website die jij wilt dat ChatGPT wordt gecrawld.
De robots.txt-richtlijnen geven de bots de opdracht om het crawlen van bepaalde secties op de website 'niet toe te staan' of 'toe te staan'. De 'Disallow'-richtlijn vertelt crawlers dat ze een specifieke pagina of submap van de website niet mogen crawlen.
Dus voordat je begint met het toestaan en weigeren van crawlers op de website, moet je ervoor zorgen dat je een goed begrip hebt van de structuur van de website en welke mappen je wel en niet wilt laten crawlen en indexeren.
Disallow: /bronnen/
In het bovenstaande voorbeeld staan we de submap ‘bronnen’ niet toe. Het bronnengedeelte van de website zou verboden terrein zijn voor robots om te crawlen.
Door gebruik te maken van de 'Allow'-richtlijn weten crawlers waar ze op de website kunnen crawlen. Tips voor richtlijnen:
Voor grote e-commercesites is het ook gebruikelijk om geparametriseerde URL's van gefacetteerde navigatie te blokkeren om index-bloat te verminderen.
Als je Shopify als een CMS gebruikt, is het belangrijk dat het wordt geleverd met een kant-en-klare robots.txt-bestandsconfiguratie die voor de meeste websites kan werken. Tot voor kort was de mogelijkheid om dit bestand te bewerken niet toegestaan, maar is ook niet mogelijk.
Naast de standaard Disallow- en Allow-richtlijnen, zijn er nog een paar richtlijnen die vaak door SEO's worden gebruikt.
Je kunt een XML-sitemap opnemen in het robots.txt-bestand met behulp van 'Sitemap:'. Deze kunnen overal worden toegevoegd, maar het beste is om ze aan het einde van het bestand te plaatsen, na alle richtlijnen. Dit zou er als volgt uitzien:
Sitemap: https://www.jouwdomein.nl/sitemap.xml-1
Sitemap: https://www.jouwdomein.nl/sitemap.xml-2
Sitemap: https://www.jouwdomein.nl/sitemap.xml-3
De Crawl-delay-richtlijn vertraagt de snelheid waarmee crawlers door de website kunnen crawlen. Dit kan worden gebruikt als je een grote website hebt en het aantal verzoeken wilt beperken dat de crawlers naar de website kunnen sturen. Dit kan voorkomen dat een crawler de servers ontmoedigt met te veel requests en mogelijk de website laat crashen. Dit komt zeer zelden voor en vereist audits van logbestanden om volledig te begrijpen hoe vaak crawlers de website bezoeken.
Vraag je af wat dat sterretje doet in het bestand Robots.txt? Dit staat bekend als een wildcard. De wildcard op zich omvat 'alles'. Het kan worden gebruikt als de user-agent om alle crawlers op te nemen of in de richtlijnen om de hele website of alles wat volgt op een map aan te duiden in een URL-structuur zoals:
User-agent: *
Disallow: /mijn-map/*
Dit blokkeert alle crawlers om alles in de categorie /mijn-map/ te crawlen.
Naast ‘*’ kun je ook een wildcard $ gebruiken om het einde van een URL-tekenreeks aan te geven. Een voorbeeld hiervan zou zijn:
User-agent: *
Disallow: /mapnaam/*.xls$
Hierdoor weten crawlers dat ze geen URL's kunnen crawlen die eindigen op .xls in /mapnaam/. Als er parameteropties zijn voor het bestand, zoals /mapnaam/bestandsnaam.xls?id=123456, dan kunnen crawlers het bestand crawlen. De '$' wordt niet veel gebruikt, omdat er verwarring kan ontstaan over het gebruik ervan en omdat sommige crawlers de richtlijn niet respecteren.
Hashtags '#' kunnen worden gebruikt om notities toe te voegen aan een robots.txt-bestand. Vergelijkbaar met het programmeren van opmerkingen die geen invloed hebben op de code, kan dit worden gebruikt om notities in het bestand achter te laten voor toekomstige menselijke gebruikers, aangezien crawlers de notities zullen negeren.
Sommige bedrijven hebben hiervan geprofiteerd en leuke notities toegevoegd aan hun robots.txt-bestanden: https://www.nike.com/robots.txt.

Andere belangrijke voorwaarden aan een correct ingesteld robots.txt-bestand:
TIP: Je kunt de grootte van het robots.txt-bestand controleren door naar het tabblad ‘Indexering’ te gaan en dan naar Google’s Robots.txt-testtool te gebruiken.
Om te zien dat pagina's worden geblokkeerd door de robots.txt-bestand, navigeer je eenvoudig naar het rapport 'Pagina's' in Google Search Console onder indexering.
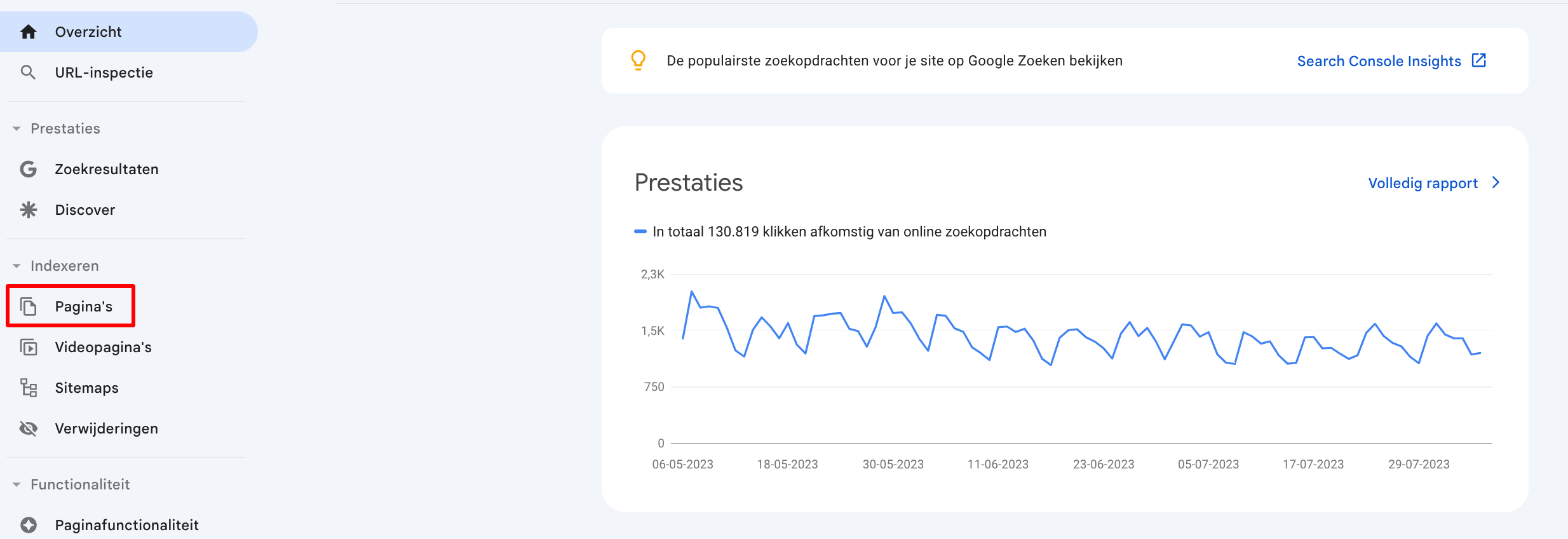
Navigeer vanaf daar naar het gedeelte 'Geblokkeerd door robots.txt'. In dit rapport zie je een lijst met de 1000 meest recente URL's die zijn geblokkeerd door een robots.txt-bestand.
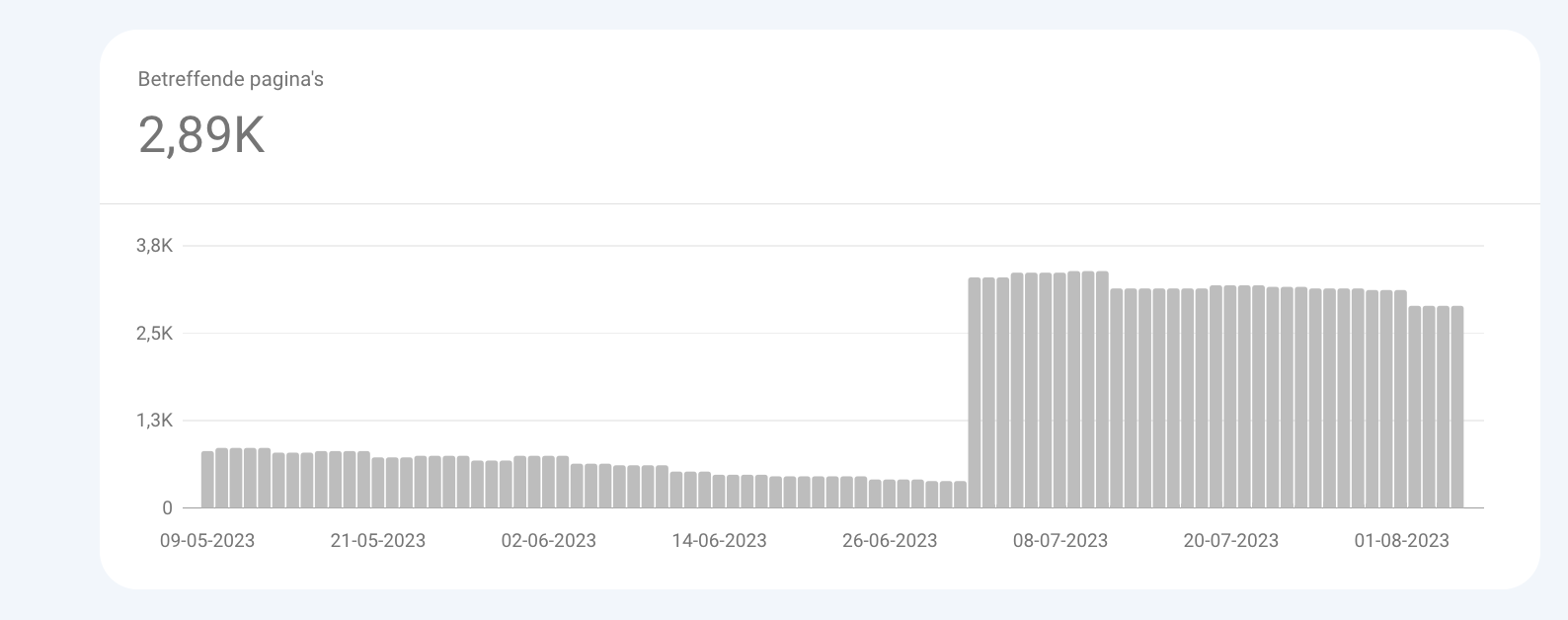
Dat URL's in dit rapport worden weergegeven, moet niet als iets negatiefs worden beschouwd, aangezien je richtlijnen kunt hebben die vereisen dat bepaalde URL's niet worden gecrawld en geïndexeerd.
TIP! Gebruik Wild cards met verschillende Google services. Robots.txt wild cards: handleiding.










