Ontdek alle mogelijkheden met ApplePY. Bekijk alle features
ChatGPT kwam als een conversational interface, waar je op een menselijke manier een chatbot vragen kunt stellen, die dit dan voor je doet of maakt. Echter, ChatGPT kan geen afbeeldingen beschrijven of zoals gezegd: een text-to-image afbeelding maken. En het kan al helemaal niet discussieren over een afbeelding.
In het afgelopen jaar is er veel onderzoek gedaan naar language models (LMs). Aan de andere kant, zijn afbeeldingen geanalyseerd door het gebruik van convolutional neural networks, totdat het afgelopen jaar een manier is gevonden op transformers met afbeeldingen te koppelen (Vision Transformers, ViTs).
Aan de ene kant zijn er vragen die niet alleen door tekst of alleen door beeld beantwoord kunnen worden, dus is er een model nodig dat de twee kan combineren. Bijvoorbeeld taken als image captioning, visuele vraagbeantwoording, en nog veel meer.
Ook is het trainen van LM's extreem duur, in feite heb je een grote hoeveelheid data en parameters nodig. De schalingswet stelt dat sommige opkomende gedragingen alleen worden opgemerkt bij een bepaald aantal parameters. Dit heeft geleid tot de wedloop naar steeds grotere en bekwamere modellen, maar toch zijn daarvoor enorm veel data nodig, zowel hardware als data. Sommige studies tonen echter aan dat zulke grote modellen misschien niet eens nodig zijn, maar dat er gewoon meer aandacht moet worden besteed aan de data.
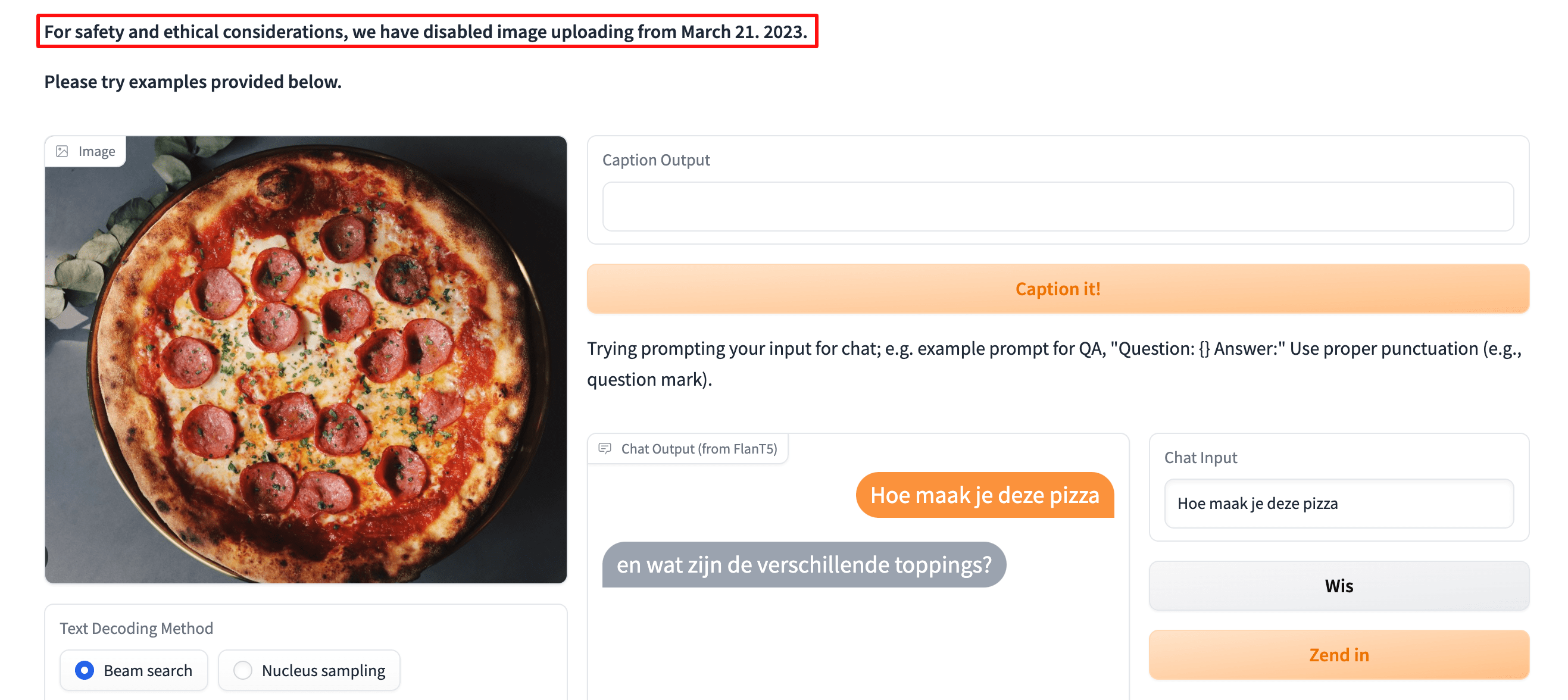
We hebben dus een model nodig dat vragen kan beantwoorden over zowel afbeeldingen als tekst (visueel model) en misschien vragen kan beantwoorden met ChatGPT, meer niet: BLIP-2 is wat je nodig hebt en het beste is dat de controlepunten er zijn op HuggingFace.
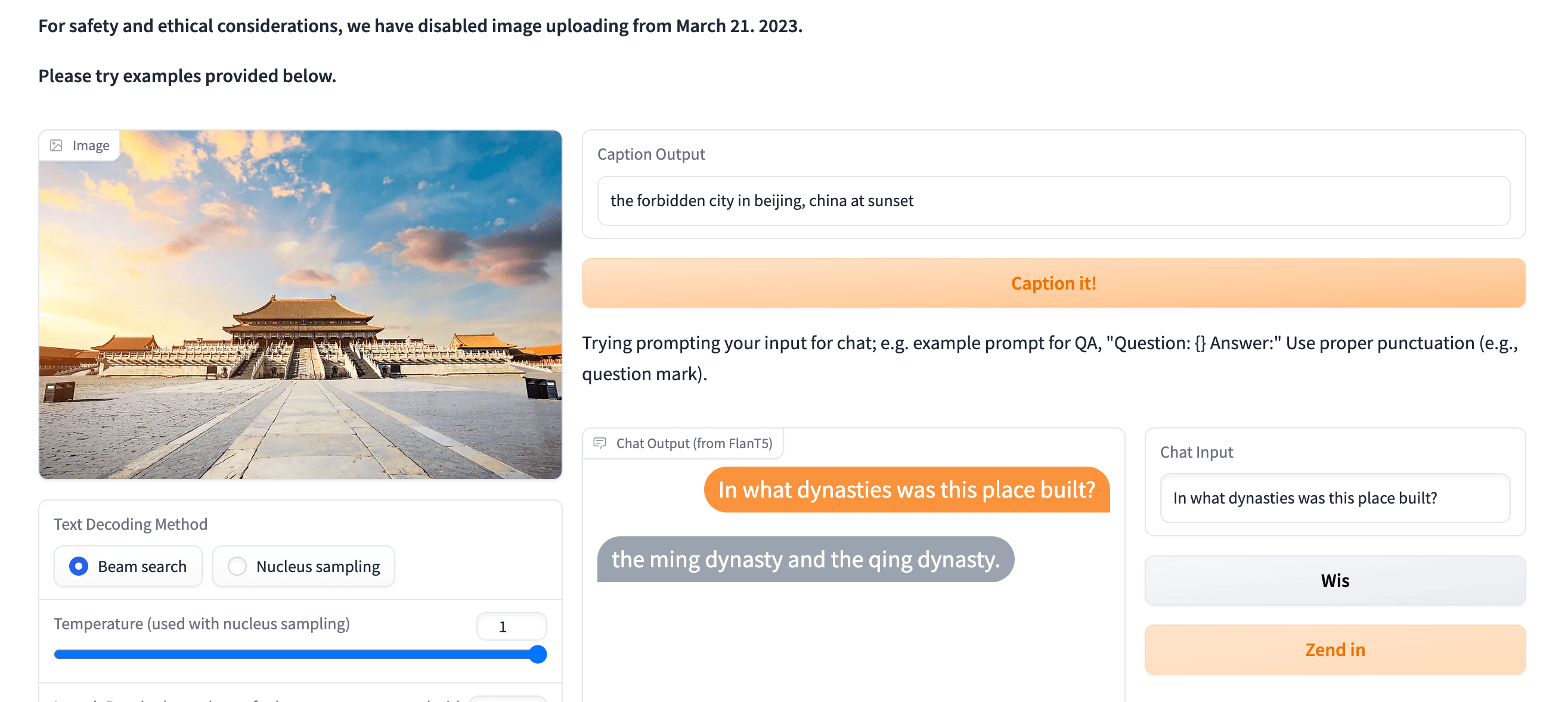
Zoals de auteurs zeggen is er enige belangstelling voor Vision-language models, maar het was duur om zo’nn model te trainen. In feite maak je een model en gebruik je zowel afbeeldingen als tekst om het te trainen, dit vereist enorme datasets van afbeeldingen en tekst.
Met andere woorden, je neemt een taalmodel en een visueel model en voegt ze samen, zonder ze zelfs maar te hoeven trainen.
Een model dat op de tekst is getraind heeft tijdens de training geen beeld gezien, en wanneer we een tekstuele vraag willen stellen over een beeld hebben we de genoemde afstemming nodig tussen de tekstuele en visuele componenten van een visueel-taalmodel (dit is trouwens het meest uitdagende deel).
Aan de andere kant, Google had Flamingo, een afbeelding-naar-tekst model, maar deze was niet efficiënt genoeg om op de markt te brengen. Daar brachten de auteurs van BLIP-2 nog enkele toevoegingen aan:










