Ontdek alle mogelijkheden met ApplePY. Bekijk alle features
Google's documentatie definieert de status 'Gecrawld – momenteel niet geïndexeerd’ als:
De pagina is door Google gecrawld, maar niet geïndexeerd. Hij kan in de toekomst wel of niet geïndexeerd worden; je hoeft deze URL niet opnieuw in te dienen voor crawling.
Het lezen van deze uitleg kan dan best frustrerend zijn, vooral als de status betrekking heeft op een pagina die belangrijk is voor het bedrijf. De definitie van Google maakt niet duidelijk wat er is gebeurd en wat je nu zou kunnen doen. Het enige wat er staat is dat Googlebot je pagina heeft gecrawld, maar om een of andere reden heeft besloten hem niet te indexeren.
Volgens ons onderzoek is de status Gecrawld - momenteel niet geïndexeerd het meest voorkomende probleem dat in het Index Coverage rapport wordt gemeld. Dit betekent dat je dit waarschijnlijk al ondervonden hebt, of dat je het in de toekomst waarschijnlijk zal ondervinden.
Het is cruciaal om het probleem zo snel mogelijk op te lossen. Immers, als je pagina niet geïndexeerd is, zal het niet verschijnen in de zoekresultaten, en het zal geen organisch verkeer van Google krijgen.
Dit artikel geeft de mogelijke oorzaken voor de status Gecrawld - momenteel niet geïndexeerd en manieren om ze te verhelpen.
Je kan de status vinden in het Index Coverage rapport en de URL inspectietool in Google Search Console.
Gevonden – momenteel niet geïndexeerd behoort tot de categorie ‘Uitgesloten’, wat aangeeft dat Google het geen goed idee vindt dat de pagina geïndexeerd wordt.
Deze pagina's worden meestal niet geïndexeerd, en wij denken dat dat terecht is. Deze pagina's zijn ofwel duplicaten van geïndexeerde pagina's, of geblokkeerd voor indexering door een of ander mechanisme op je website, of anderszins niet geïndexeerd om een reden waarvan wij denken dat het geen fout is.
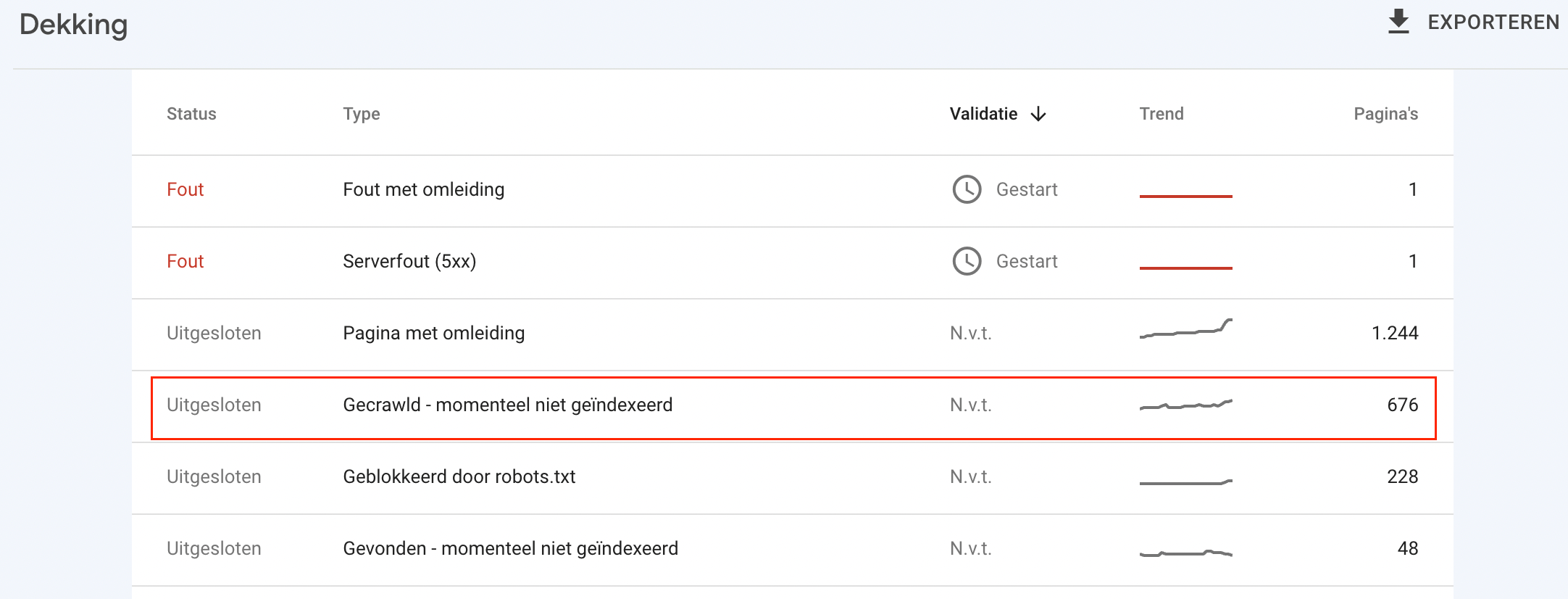
Nadat je op de status Gecrawld - momenteel niet geïndexeerd hebt geklikt, zie je een lijst met getroffen URL's. Je moet deze bekijken en prioriteit geven aan het oplossen van het probleem voor pagina's die voor jou het meest waardevol zijn.
Het rapport is ook beschikbaar voor export. Je kunt echter maar tot 1000 URL's exporteren. Als er meer pagina's getroffen zijn, kan je het aantal geëxporteerde URL's verhogen door pagina's te filteren die specifiek zijn voor sitemaps. Bijvoorbeeld, als je twee sitemaps hebt, elk met 1000 URL's, kan je ze allebei apart exporteren.
De URL inspectietool in Google Search Console kan je ook informeren over URL’s die Gecrawld - momenteel niet geïndexeerd zijn.
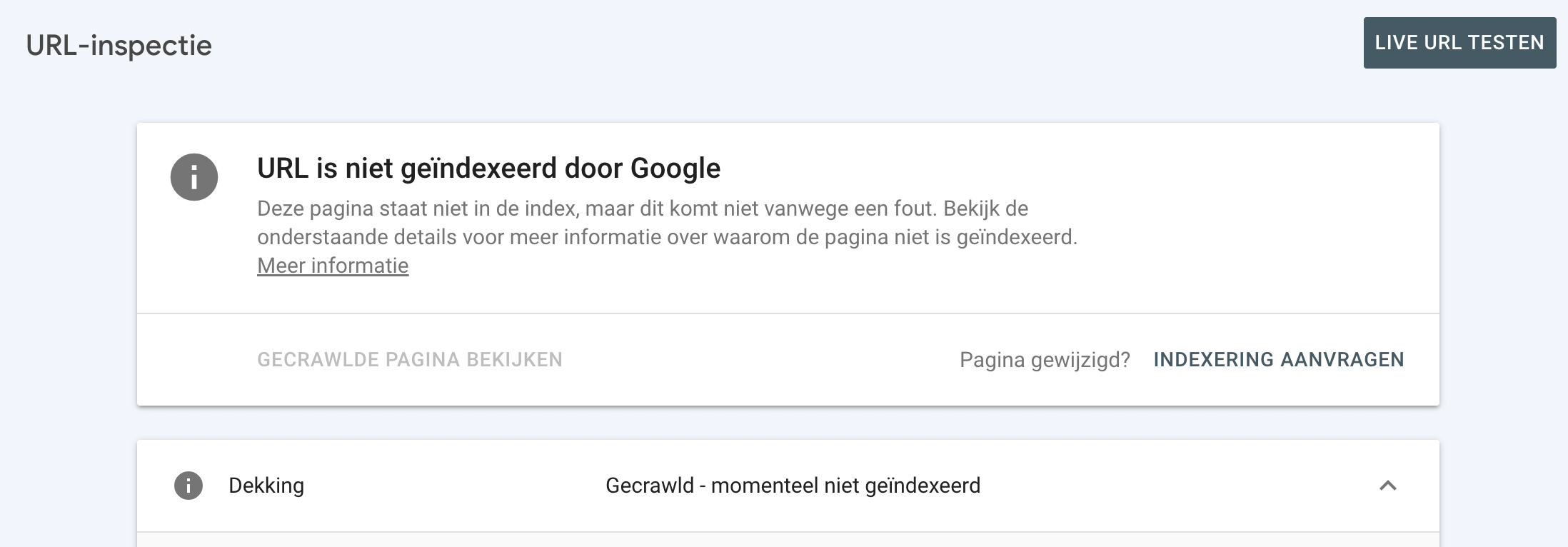
Het bovenste gedeelte van de tool informeert je of de URL gevonden kan worden op Google of niet. Als de geïnspecteerde URL behoort tot de categorie Uitgesloten in het rapport Indexdekking, zal de URL inspectietool het volgende rapporteren: ‘De pagina staat niet in de index, maar niet vanwege een fout’.
Hieronder vind je meer specifieke informatie over de huidige dekkingsstatus van de geïnspecteerde URL - in het geval hierboven was de URL crawled - momenteel niet geïndexeerd.
Na het opmerken van de Gecrawld - momenteel niet geïndexeerd status, is het eerste wat je zou moeten doen onderzoeken of je pagina werkelijk niet geïndexeerd is.
Het is niet ongewoon om een pagina gemarkeerd te zien als Gecrawld - momenteel niet geïndexeerd in het Index Coverage rapport, terwijl de URL inspectietool aangeeft dat de pagina daadwerkelijk geïndexeerd is.
De URL inspectietool stelt je in staat om details over een specifieke URL te controleren, inclusief:
Je kan ook indexering aanvragen voor een URL of een gerenderde versie van een pagina bekijken.
Google's John Muller behandelde het probleem met verschillen tussen het Index Coverage rapport en URL inspectietool tijdens Google's SEO Office Hours:
Ik heb onlangs een aantal threads zoals deze gezien op Twitter waar mensen URL's zagen die gemarkeerd waren als niet geïndexeerd in Search Console. En dan, als je ze individueel controleert, zijn ze daadwerkelijk geïndexeerd. Ik weet nog niet precies wat daar gebeurt. […]
Mijn vermoeden is dat het meer een kwestie van timing is – laten we ze zien in het Search Console rapport, en dan worden ze na verloop van tijd geïndexeerd. Dan op een gegeven moment, zouden ze weer uit het rapport verdwijnen. En om wat voor reden dan ook, duurt het uit het rapport halen iets langer dan het zou moeten.
Zoals John zei, kan het gewoon een vertraging zijn en een probleem met de synchronisatie van gegevens tussen deze twee instrumenten, en de status kan na verloop van tijd worden bijgewerkt in het Index Coverage rapport.
Het is echter niet altijd alleen maar een vertraging. Soms is het een fout in de rapportage. In september merkten we dat sommige van onze geïndexeerde artikelen de melding Gevonden – momenteel niet geïndexeerd kregen.
Dat was zeker geen vertragingskwestie, want oude artikelen werden ook aangetast. Kort daarna begonnen andere SEO's, waaronder Lily Ray, ditzelfde probleem op te merken.
Over het algemeen toont de URL inspectietool actuele gegevens dan het Index Coverage rapport. Daarom moet je altijd meer vertrouwen hebben in de URL inspectietool wanneer je tussen deze rapporten moet kiezen.
Nu, laten we het probleem tot op de bodem uitzoeken – wat veroorzaakt deze status en wat je kan doen om het op te lossen.
Google geeft geen duidelijk antwoord waarom je pagina wel werd gecrawld maar niet geïndexeerd, maar er zijn een paar mogelijke redenen waarom de status zou kunnen verschijnen, waaronder:
Het is niet ongewoon dat Google een pagina bezoekt, maar er een tijdje over doet om hem te indexeren. Het internet is oneindig groot, en Google moet voorrang geven aan welke pagina's het eerst worden geïndexeerd.
Als je je pagina net hebt gepubliceerd, kan het heel normaal zijn dat deze nog niet geïndexeerd is, en dat je nog wat langer moet wachten voordat Google je content indexeert.
Je kan het crawlen en indexeren van je pagina op korte termijn niet beïnvloeden, maar er zijn wel een paar dingen die je kan doen om je website op de lange termijn te helpen:
Google kan niet alle pagina's op het internet indexeren. Zijn opslagruimte is beperkt, en daarom moet het de content van lage kwaliteit eruit filteren.
Het doel van Google is om pagina's van de hoogste kwaliteit aan te bieden die het beste beantwoorden aan de intentie van gebruikers.
Dit betekent dat als een pagina van mindere kwaliteit is, Google deze waarschijnlijk zal negeren om de opslagruimte vrij te houden voor content van hogere kwaliteit. En we kunnen verwachten dat de kwaliteitsnormen in de toekomst alleen maar strenger zullen worden.
Als website-eigenaar moet je ervoor zorgen dat je pagina content van hoge kwaliteit biedt. Controleer of het waarschijnlijk is dat het voldoet aan de intentie van je gebruikers en voeg indien nodig content van goede kwaliteit toe. Google biedt een lijst met vragen om je te helpen de waarde van je content te bepalen. Dit zijn er enkele van:
Daarnaast kan je tips over kwaliteitscontent gebruiken uit Google's Quality Raters Guidelines. Hoewel het document vooral bedoeld is voor Search Quality Raters om de kwaliteit van een website te beoordelen, kunnen webmasters het gebruiken om inzicht te krijgen in hoe ze hun eigen site kunnen verbeteren. Als je meer wil weten, bekijk dan onze gids over Quality Raters Guidelines.
User generated content kan een probleem vormen vanuit het oogpunt van kwaliteit. Laten we bijvoorbeeld aannemen dat je een forum hebt en dat iemand een vraag stelt. Ook al zouden er in de toekomst veel waardevolle antwoorden komen, op het moment van crawlen was dat niet het geval, dus Google kan de pagina classificeren als content van lage kwaliteit.
Wat kan je doen om je tegen deze situatie te beschermen? Quora heeft een uitstekende strategie voor dit probleem bedacht. Elke onbeantwoorde vraag heeft het voorvoegsel "/unanswered/" in de URL.
Het robots.txt bestand blokkeert alle pagina's met /unanswered/ in hun URLs. Dit betekent dat Googlebot ze niet kan crawlen.
Zodra er een antwoord op de vraag is, verandert de URL en wordt deze beschikbaar voor crawling. Op deze manier blokkeert Quora de toegang tot de content van lage kwaliteit die door de gebruikers wordt gegenereerd.
Een URL kan de status Gevonden – momenteel niet geïndexeerd hebben omdat hij in het verleden wel geïndexeerd was, maar Google besloot om deze na verloop van tijd niet meer te indexeren.
Als je je afvraagt waarom sommige dingen uit de index kunnen verdwijnen, is het waarschijnlijk dat ze gewoon vervangen zijn door content van hogere kwaliteit.
Daarnaast moet je letten op algoritme-updates. Het is mogelijk dat er een nieuw algoritme is uitgerold, en dat je pagina hierdoor is beïnvloed.
De oplossing voor pagina’s die zijn gedeïndexeerd is nauw verbonden met de kwaliteit ervan. Je moet er altijd voor zorgen dat je pagina content heeft van de beste kwaliteit en up-to-date is. Ga er niet van uit dat als een pagina eenmaal is geïndexeerd, je er nooit meer iets mee hoeft te doen. Blijf de pagina monitoren en voer indien nodig veranderingen en verbeteringen door.
[…] pagina's die dalen na een core update hebben niets fout te herstellen. Dit gezegd hebbende, begrijpen we dat degenen die het minder goed doen na een verandering in de core update misschien toch het gevoel hebben dat ze iets moeten doen. We stellen voor dat je je concentreert op het aanbieden van de best mogelijke content. Dat is wat onze algoritmen proberen te belonen.
Nadat je de problemen hebt opgelost, kan je deze URL's indienen bij Google Search Console zodat Google de wijzigingen sneller opmerkt.
Toen John Mueller werd gevraagd naar mogelijke redenen waarom een pagina de status Gecrawld - momenteel niet geïndexeerd kreeg, noemde hij een andere mogelijke oorzaak - slechte websitestructuur.
Laten we ons een situatie voorstellen waarin je een pagina hebt van goede kwaliteit, maar de enige manier waarop Google die heeft gevonden is omdat je hem in je sitemap hebt gezet.
Google zou de pagina kunnen bekijken en crawlen, maar omdat er geen interne links zijn, zou het aannemen dat de pagina minder waarde heeft dan andere pagina's. Er is geen semantische of structurele informatie om de pagina te evalueren. Dat zou een van de redenen kunnen zijn waarom Google besloten heeft om zich op andere pagina's te concentreren en deze pagina buiten de index te laten.
Een goede website-architectuur is de sleutel tot het maximaliseren van de kansen om geïndexeerd te worden. Het stelt zoekmachine bots in staat om je content te ontdekken en de relatie tussen pagina's beter te begrijpen.
Daarom is het cruciaal om te zorgen voor een goede website architectuur en ervoor te zorgen dat er interne links zijn naar de pagina die je geïndexeerd wilt hebben.
Google wil unieke en waardevolle content aan gebruikers presenteren. Als Google tijdens het crawlen merkt dat sommige pagina's identiek of bijna identiek zijn, indexeert het er misschien maar één.
Meestal wordt de andere als "Duplicate" gelabeld in het Index Coverage rapport. Dit is echter niet altijd het geval, en soms geeft Google in plaats daarvan de status Gecrawld - momenteel niet geïndexeerd.
Het is niet helemaal duidelijk waarom Google Gecrawld - momenteel niet geïndexeerd zou verkiezen boven een specifieke status voor dubbele content. Een van de mogelijke verklaringen is dat de status later verandert nadat Google heeft besloten of er een geschikte status is voor de pagina.
Een andere mogelijkheid zou een fout in de rapportage kunnen zijn. Google zou gewoon een fout kunnen maken bij het toekennen van de statussen. Helaas is de situatie lastiger omdat Gecrawld - momenteel niet geïndexeerd niet zo veel informatie geeft als een speciale status voor dubbele content.
Hoe kan ik controleren of een dubbele pagina in de zoekresultaten wordt getoond?
Eerst en vooral moet je ervoor zorgen dat je originele pagina's maakt. Voeg unieke content toe indien nodig. Helaas kan dubbele content onvermijdelijk zijn (je hebt bijvoorbeeld een mobiele en desktopversie). Je hebt niet veel controle over wat er in de zoekresultaten verschijnt, maar je kunt Google wel wat hints geven over de originele versie.
Als je merkt dat er veel dubbele content wordt geïndexeerd, evalueer dan de volgende elementen:
|
Gecrawld – momenteel niet geïndexeerd |
Gevonden – momenteel niet geïndexeerd |
|
|
Pagina ontdekt door Google |
Ja | Ja |
|
Pagina bezocht door Google |
Ja | Nee |
|
Pagina geïndexeerd |
Nee | Nee |
Sommige van de redenen voor deze statussen kunnen vergelijkbaar zijn, waaronder pagina's van slechte kwaliteit en problemen met interne links. Wanneer je echter een status Gevonden - momenteel niet geïndexeerd ziet, moet je ook onderzoeken waarom Google de pagina niet kon of wilde bekijken. Het kan bijvoorbeeld wijzen op problemen met de algehele kwaliteit van de hele website, crawlbudget of overbelasting van de server.
Gecrawld - momenteel niet geïndexeerd wordt voornamelijk geassocieerd met de kwaliteit van de pagina, maar in werkelijkheid kan het op veel meer problemen wijzen, zoals website architectuur of dubbele content.
Hier zijn de belangrijkste punten uit het artikel die je kunnen helpen om te gaan met de status Crawled - momenteel niet geïndexeerd:
De Google Indexing API is een tool die door Google wordt aangeboden en waarmee ontwikkelaars URL's kunnen indienen voor het crawlen en indexeren van de Google-zoekmachine. Met deze API kunnen ontwikkelaars verzoeken dat Google hun website-inhoud sneller en efficiënter crawlt en indexeert dan traditionele methoden, zoals het indienen van een sitemap of wachten tot Google de pagina's zelf ontdekt.
De Google Indexing API is vooral nuttig voor websites die regelmatig hun inhoud updaten, zoals nieuwswebsites, blogs en e-commerceplatforms. Door deze API te gebruiken, kunnen ontwikkelaars ervoor zorgen dat nieuwe inhoud snel wordt ontdekt en geïndexeerd door Google, wat kan helpen om het verkeer naar hun website te vergroten en hun zoekmachineposities te verbeteren. Met ApplePY heb je deze technische kennis niet nodig. Ga direct nog aan de slag:
Het uitdagende van deze melding in GSC ligt in het debuggen vanwege het variërende spectrum van factoren die bijdragen aan het activeren van deze melding:










