Ontdek alle mogelijkheden met ApplePY. Bekijk alle features
De interne linkstructuur op een website is erg belangrijk. Het zorgt ervoor dat Google de pagina’s kan crawlen wat weer zorgt voor meer geïndexeerde pagina’s. En dus ook voor meer traffic. Deze linkjes helpen Google zowel pagina's te ontdekken als rankings toe te wijzen op basis van een aantal rankingparameters. Een pagina met 100 interne links bijvoorbeeld, heeft vermoedelijk een hogere prioriteit dan een pagina met een enkele link.
Pagina's op je site zijn gegroepeerd aan de hand van de canonieke URL. Dit betekent dat de ankertags en mogelijk een aantal parameters zijn weggelaten voordat de groepering wordt uitgevoerd. Bekijk de technisch SEO template in een spreadsheet.
Maar geen van beide - ontdekken van nieuwe pagina’s en ranking - is mogelijk als Googlebot de links niet kan crawlen. Dit kan drie oorzaken hebben:
Zelfs als een pagina is geïndexeerd, kun je er nooit zeker van zijn dat de links van of naar die pagina correct te crawlen zijn en dus link equity doorgeven. Hier volgen drie manieren om ervoor te zorgen dat Googlebot links op de website kan crawlen.
De tekstcache van Google. De tekstversie van Google Cache geeft weer hoe Google een pagina ziet met CSS en JavaScript uitgeschakeld. Het is niet hoe Google een pagina indexeert, aangezien het die pagina's nu kan begrijpen zoals mensen ze waarnemen. Een website met weinig URLs hoeft zich geen zorgen te maken dat een website met wat JavaScript niet goed gecrawld wordt. Uit onderzoek blijkt dat JavaScript rendering 9x meer resources kost dan simpel HTML.
De tekstcache van een pagina is dus een uitgeklede versie. Toch is het de meest betrouwbare manier om te bepalen of Google jouw links kan crawlen. Als die links zich in de cache met alleen tekst bevinden, kan Google ze crawlen.
TIP! Met ApplePY heb je heel veel extra scripts om topic clusters aan te maken. Maar ook nog meer dan 50+ andere scripts voor andere toepassingen. Er zijn talloze scripts en elke maand komen daar weer nieuwe scripts bij. Probeer ApplePY de eerste 7 dagen gratis.
Naast alleen tekst bevat Google Cache de geïndexeerde versie van een pagina. Het is een handige manier om ontbrekende elementen op de mobiele versie te identificeren.
Veel zoekoptimalisaties negeren Google Cache. Alle essentiële ranking-elementen zijn aanwezig. Er is geen andere manier om ervoor te zorgen dat Google over die belangrijke informatie beschikt.
Om toegang te krijgen tot de tekstversie van Google Cache op een pagina, zoek je op Google naar cache:[full-URL] en klik je op Tekstversie'.
Om toegang te krijgen tot de tekstversie van Google Cache, zoek je op Google naar cache:[full-URL] en klik je op ‘Tekstversie'.
Niet alle pagina's verschijnen in Google Cache. Als een pagina ontbreekt, gebruik dan 'URL inspecteren' in Search Console of browserextensies voor details over hoe Google deze weergeeft.
'URL-inspectie' in Search Console toont elke pagina zoals Google die waarneemt. Voer de URL in en klik vervolgens op 'Gecrawlde pagina weergeven'.
Kopieer vanaf daar de HTML die Google gebruikt om de pagina te lezen. Plak die HTML in een document zoals Google Docs en zoek (CTRL+F op Windows of CMD+F op Mac) naar de link-URL's die jij wilt verifiëren. Als de URL's in de HTML-code staan, kan Google ze crawlen.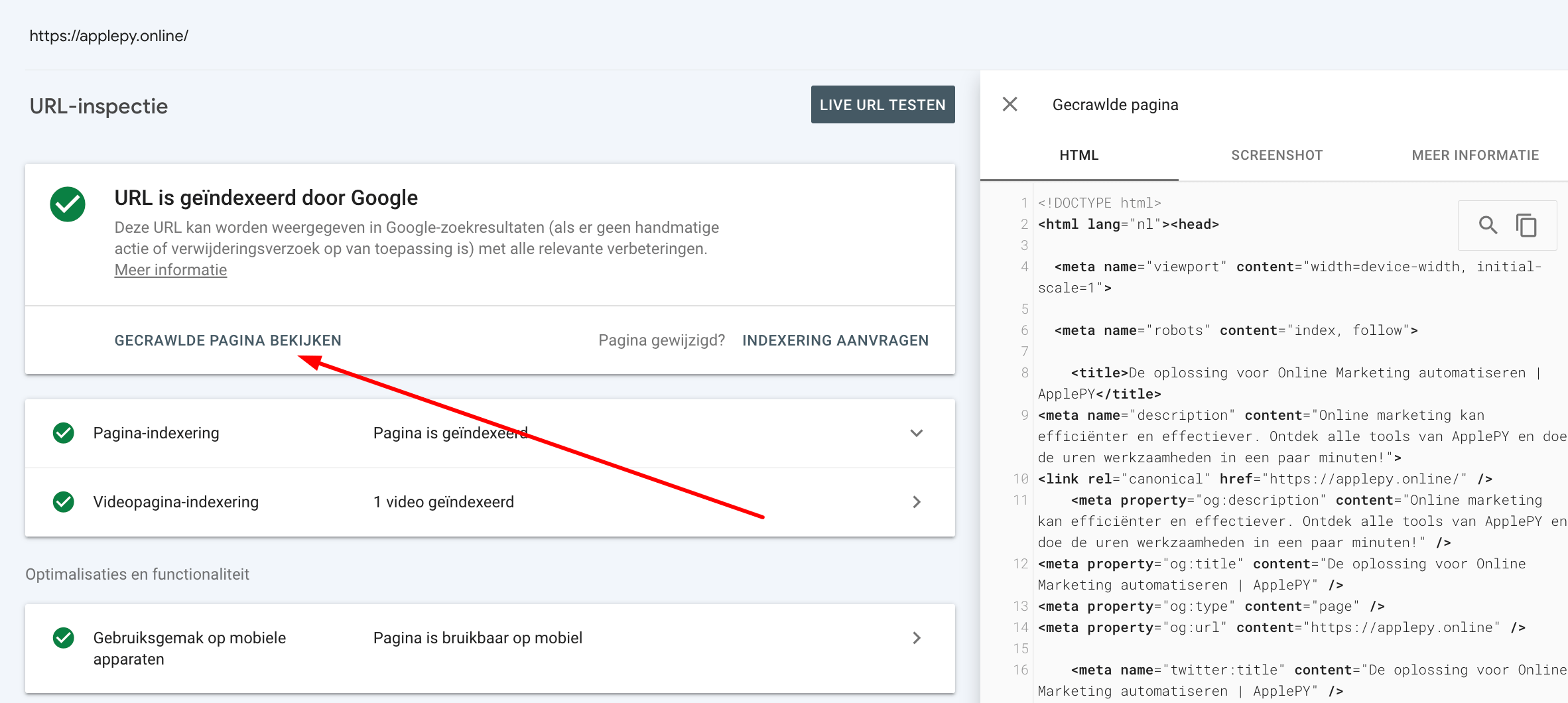
Browser-extensies. Nadat je hebt bevestigd dat Google de links kan zien, controleer je of ze kunnen worden gecrawld. Als je de code bekijkt, worden zowel het nofollow als de metatag geïdentificeerd. Firefox heeft een tool om de HTML van een pagina te laden via CTRL+U op Windows en CMD+U op Mac. Zoek vervolgens naar "nofollow" in de broncode.
De NoFollow-browserextensie - beschikbaar voor Firefox en Chrome - markeert nofollow - links terwijl een pagina wordt geladen - in een attribuut en een metatag.
Geen van deze methoden geeft definitief aan of de links van invloed zijn op de rainking. Het algoritme van Google is zeer geavanceerd en kent naar eigen keuze betekenis en gewicht toe aan links, inclusief het negeren ervan. Desalniettemin is het openen en doorzoeken van links de eerste stap van Google.










