Ontdek alle mogelijkheden met ApplePY. Bekijk alle features
Tegenwoordig is er zoveel informatie beschikbaar waar bedrijven gebruik van kunnen maken. Zodra dergelijke data zijn verkregen, wordt een spectrum aan analysetechnieken beschikbaar gesteld. De probleemstelling wordt als volgt beschreven:
Gegeven een reeks klanten, welke overeenkomsten en verschillen zijn er tussen hen, en welke groepen ontstaan als resultaat?
De oplossing hiervoor helpt bij het beantwoorden van de hogere vraag hoe het bedrijf kan profiteren van deze groepen om een aantal doelen te bereiken, zoals klanttevredenheid en retentie of gerichte marketing.
In deze analyse maken we een concept om onze klantgegevens te verrijken met statistieken met behulp van RFM-analyse, en om voorspellende statistieken zoals Lifetime Value en Churn Risk op te nemen.
Laten we de stappen doornemen:
We beginnen met het verzamelen van transactiedata, zoals een klant-ID, transactiedatums en de transactiewaarde.
We kunnen de datum gebruiken om de dag van de week, de maand, het uur en alle op tijd gebaseerde functies met betrekking tot elke transactie te extraheren. Als er verschillende categorieën transacties zijn, kunnen die kolommen ook worden ingebracht.
Als we alleen naar deze basistransactiekolommen kijken, zijn er een paar statistieken op klantniveau die we in de volgende stap kunnen berekenen.
De taak om items samen te groeperen kan niet volbracht worden zonder de basis van die groepering te bepalen. Met andere woorden, er moet een reden zijn om een item in de ene groep te plaatsen en niet in een andere.
Deze stap bestaat uit het verzamelen, berekenen en voorspellen van zinvolle statistieken. of 'kenmerken', waarop de klanten worden gegroepeerd.
Kortom, we gebruiken de transactiegegevens gewoon om te bepalen:
In dit voorbeeld gebruiken we dagen als onze eenheid van duur. (Als een klant bijvoorbeeld 131 jaar oud is, betekent dit dat hij 131 dagen geleden voor het eerst met het bedrijf in aanraking is gekomen).
| Customer_ID | Recency | Frequency | Age | Value |
| 1 | 131 | 1 | 8.145000 | 131 |
| 2 | 69 | 1 | 7.770000 | 69 |
| 3 | 121 | 1 | 3.640000 | 121 |
| 5 | 4 | 4 | 14.672500 | 100 |
Nu hebben we enkele functies die het klantenbestand beschrijven. Laten we ook enkele op tijd gebaseerde functies berekenen. In wezen proberen we te bepalen wanneer klanten het liefst met het bedrijf in contact komen - en het effect van de datum op die voorkeuren.
# Extract day, month, day of week and day of year from Transaction Date. df is the transaction table.
def get_temporal_features(df, date_col, id_col):
# Get Dates and IDs of each transaction
temp = df[[id_col, date_col]]
# Get Day of Week
temp['DayOfWeek'] = temp[date_col].dt.day_name()
# Get Month Name
temp['Month'] = temp[date_col].dt.month_name()
# One hot encode using dummies
dummies = pd.get_dummies(temp[['DayOfWeek', 'Month']])
dummies[id_col] = df[id_col].values
# Aggregate by customer
dummies = dummies.groupby(id_col).sum()
return dummies
In de bovenstaande code zullen we de volgende temporele kenmerken van de transacties berekenen:
Voor de DayOfWeek zou dit er ongeveer zo uit kunnen zien:
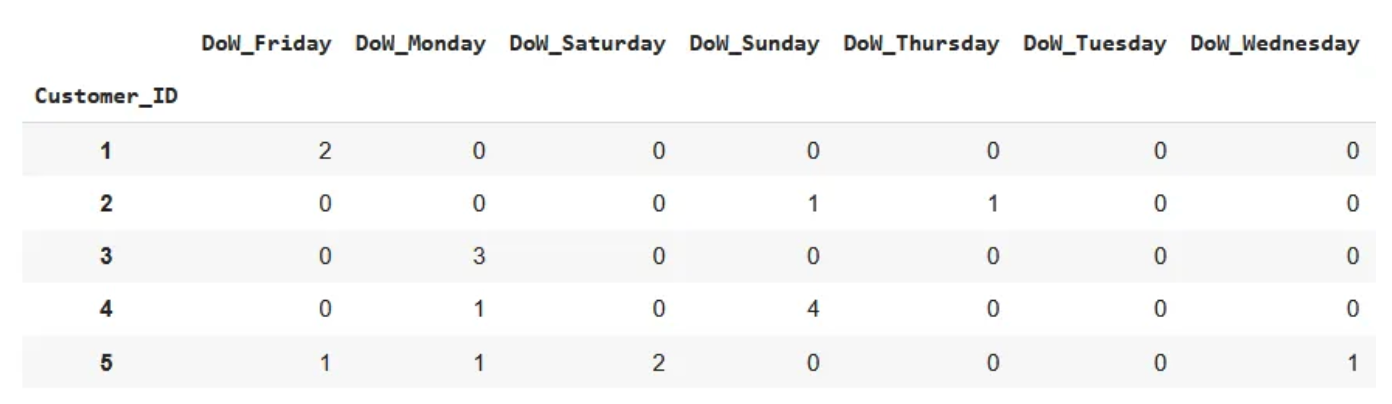
Hier heeft Klant 1 in totaal twee keer gekocht, beide op een vrijdag, terwijl Klant 2 ook 2 transacties heeft gedaan, maar één op zondag en één op donderdag. Deze logica wordt op dezelfde manier toegepast op de Maanden.
Nu kunnen we al het andere berekenen waarvoor we statistieken hebben op klantniveau, en ook andere voorspelde statistieken invoeren, zoals Churn Risk en Predicted Lifetime Value.
We doen dit door de modellen te importeren die we al geschikt hebben voor deze taak, en voorspellen eenvoudigweg de functies die we voor elke klant hebben gegenereerd. Een korte samenvatting van de modellen die we hebben getraind:
Aangezien we onze modellen passen op de RFM-functies die we hebben gemaakt, is dit eenvoudig:
import pickle
# Load Churn Risk and Lifetime value predictive models
churn_model = pickle.load(open(churn_model_path, 'rb'))
ltv_model = pickle.load(open(ltv_model_path, 'rb'))
# Append predictions to current data
rfm[['buy_prob', 'churn_risk']] = churn_model.predict(rfm)
rfm['pred_spend'] = ltv_model.predict(rfm)
Voel je vrij om andere functies in te brengen die je maar kunt bedenken en die op klantniveau kunnen worden geaggregeerd. Hier heb ik to_date_value opgenomen, waarmee de totale waarde van de klant wordt gecodeerd.
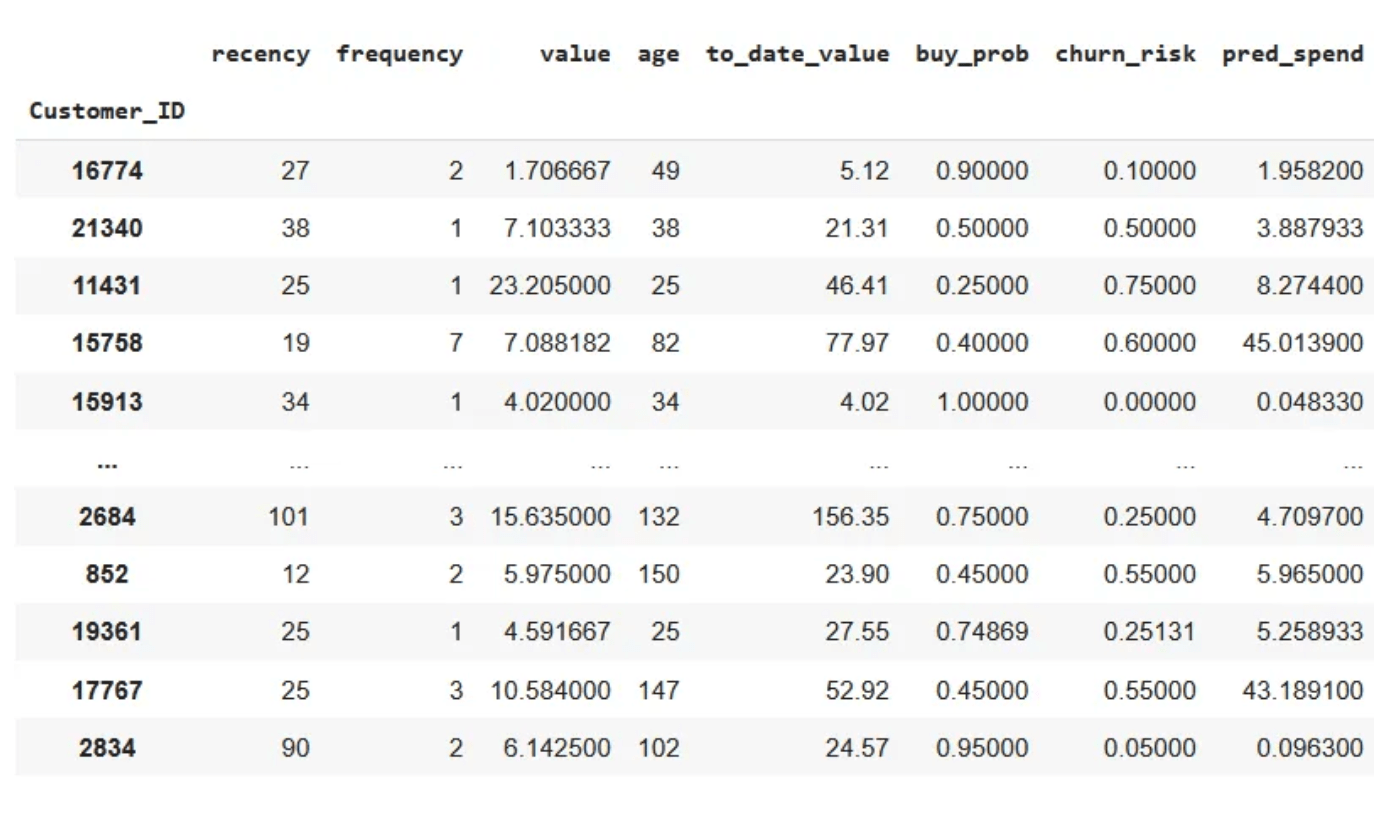
Laten we alle functies die we hebben consolideren en alles samenvoegen op klant-ID. Nu al onze beschrijvende statistieken klaar zijn, kunnen we beginnen met het 'clusteren' van de klanten.
Clustering is een soort leeralgoritme zonder toezicht, een tak van machine learning. Hoewel er geen echte waarde of label is om te voorspellen, is het doel om inzichtelijke manieren te vinden om de datapunten die we hebben te groeperen.
Er zijn 4 hoofdtypen clusteralgoritmen: op zwaartepunt gebaseerd, op dichtheid gebaseerd, op distributie gebaseerd en hiërarchisch. We gebruiken K-means clustering, omdat het gemakkelijk te interpreteren is en een intuïtief concept heeft. Het nadeel van dit soort algoritme is dat het gevoelig is voor beginvoorwaarden die enigszins kunnen worden verzacht door willekeur en herhaling.
We kunnen het algoritme als volgt omschrijven:
Gelukkig heeft scikit-learn een klasse die dit algoritme al heeft geïmplementeerd, hoewel wij je ten zeerste aanraden om het zelf ook als oefening te implementeren.
Het K-means-algoritme vereist wel een argument, namelijk het aantal te vinden clusters. Vaak is dit echter niet bekend. Hoeveel groepen is tenslotte het meest beschrijvende aantal groepen? Hier introduceren we de 'Elleboog Methode'. Hier zullen we eenvoudigweg meerdere K-means-algoritmen passen met een toenemend aantal groepen om te vinden, en de som van de gekwadrateerde afstanden berekenen en uitzetten tegen het aantal gebruikte groepen.
from sklearn.cluster import KMeans
sq_distances = []
K = range(1,15)
for k in K:
km = KMeans(n_clusters=k)
km = km.fit(_features)
sq_distances.append(km.inertia_)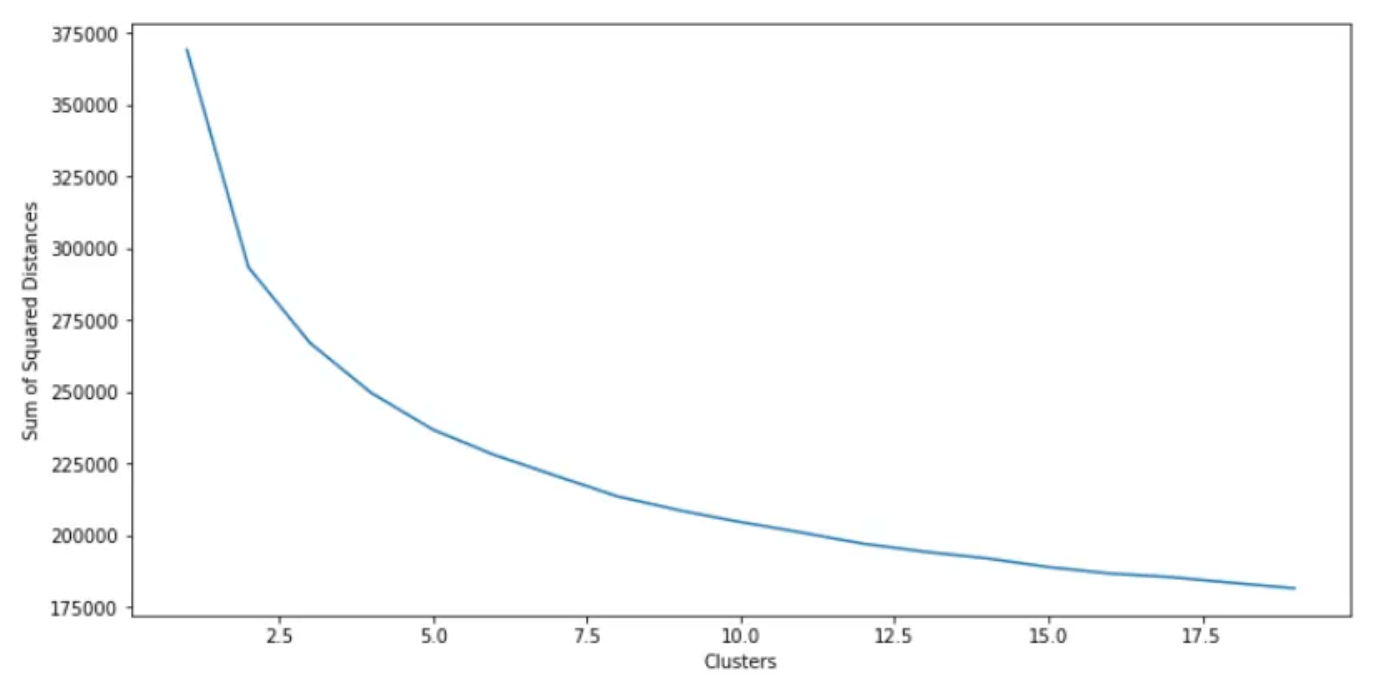
We zijn op zoek naar de piek van de bocht, die optreedt bij ongeveer 3-4 clusters, wat aangeeft dat dit het ideale aantal clusters is om in het K-means-algoritme te passen.
Aangezien het K-means clusteringalgoritme willekeurig wordt geïnitialiseerd, kunnen de namen van de clusters elke keer anders zijn. Als de clustering echter robuust is, merk je dat de daadwerkelijke clusters zelf dezelfde eigenschappen hebben en dat de namen zijn verwisseld. We zullen deze bekijken door de centra van elk cluster te berekenen om de gemiddelde waarde voor elk kenmerk te krijgen en deze tussen clusters te vergelijken.
De grafieken hieronder tonen de centra van elk van de 3 clusters (hierin aangeduid als 0, 1 en 2). We hebben ze opgesplitst voor zichtbaarheid:
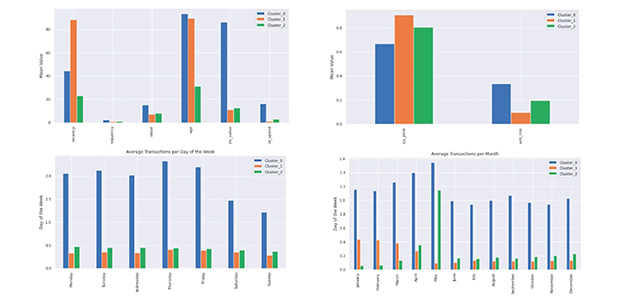
Aantal klanten in elk cluster:
Elke dataset is anders en wordt anders geclusterd. Het K-means-algoritme wordt gebruikt om groepen binnen de data te vinden, maar we moeten nog de vraag beantwoorden wat deze groepen vertegenwoordigen. Laten we het intuïtief doornemen. De onderstaande matrix toont dezelfde data als hierboven, behalve dat het aangeeft hoe hoog of laag elk kenmerk is ten opzichte van de andere clusters. Elke functie is genormaliseerd voor de duidelijkheid.
Laten we de bovenstaande data interpreteren:
Er zijn meer kwantitatieve manieren om de eigenschappen van de clusters die we hebben gemaakt te interpreteren. Dit biedt een manier om de interpretatie van de clusters te automatiseren.
Het uitvoeren van een K-means clusteringanalyse op basis van je eigen CRM-gegevens kan je helpen om meer inzicht te krijgen in je klantenbestand en gepersonaliseerde marketingstrategieën te ontwikkelen om je bedrijf te laten groeien. Het is belangrijk om de gegevens goed te verzamelen, te pre-processen, het aantal clusters te bepalen, de analyse uit te voeren, de resultaten te interpreteren en te implementeren in je bedrijfsstrategie. Meer informatie over K-means clustering.
TIP! Met ApplePY heb je heel veel extra scripts om topic clusters aan te maken. Maar ook nog meer dan 50+ andere scripts voor andere toepassingen. Er zijn talloze scripts en elke maand komen daar weer nieuwe scripts bij. Probeer ApplePY gratis.










